Now in private beta · macOS 14+
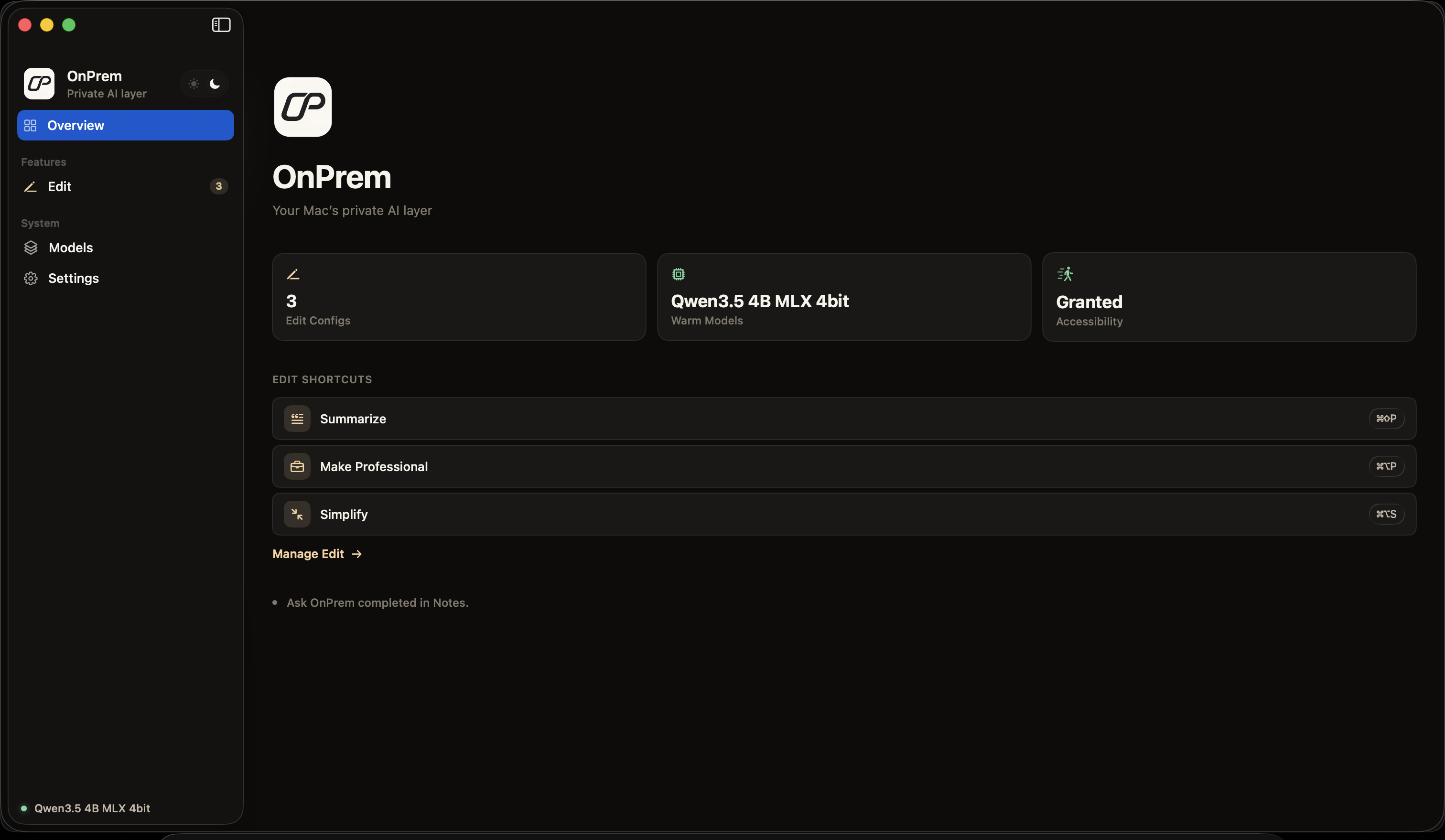
Your Mac's private
Your Mac's private
AI layer.
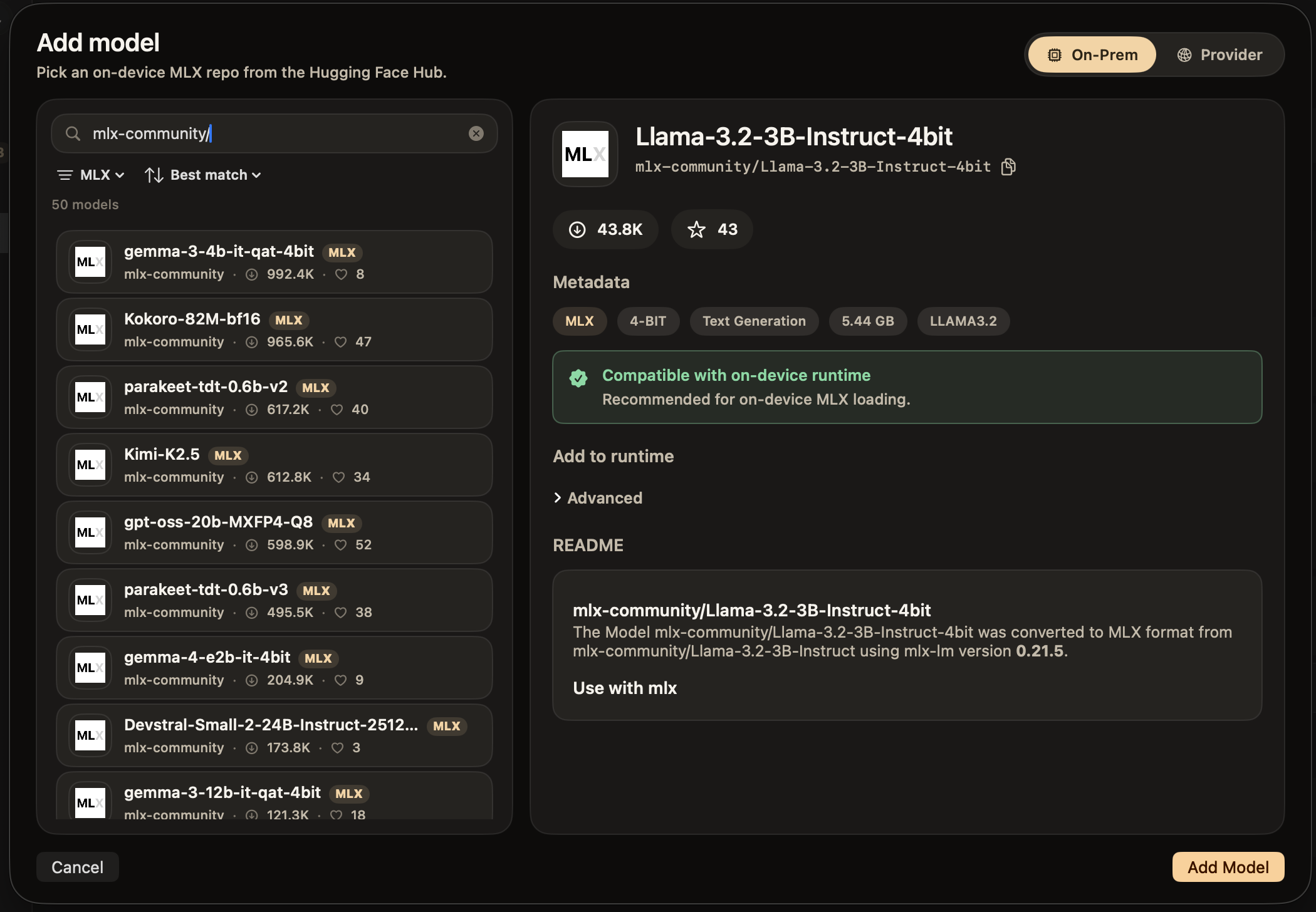
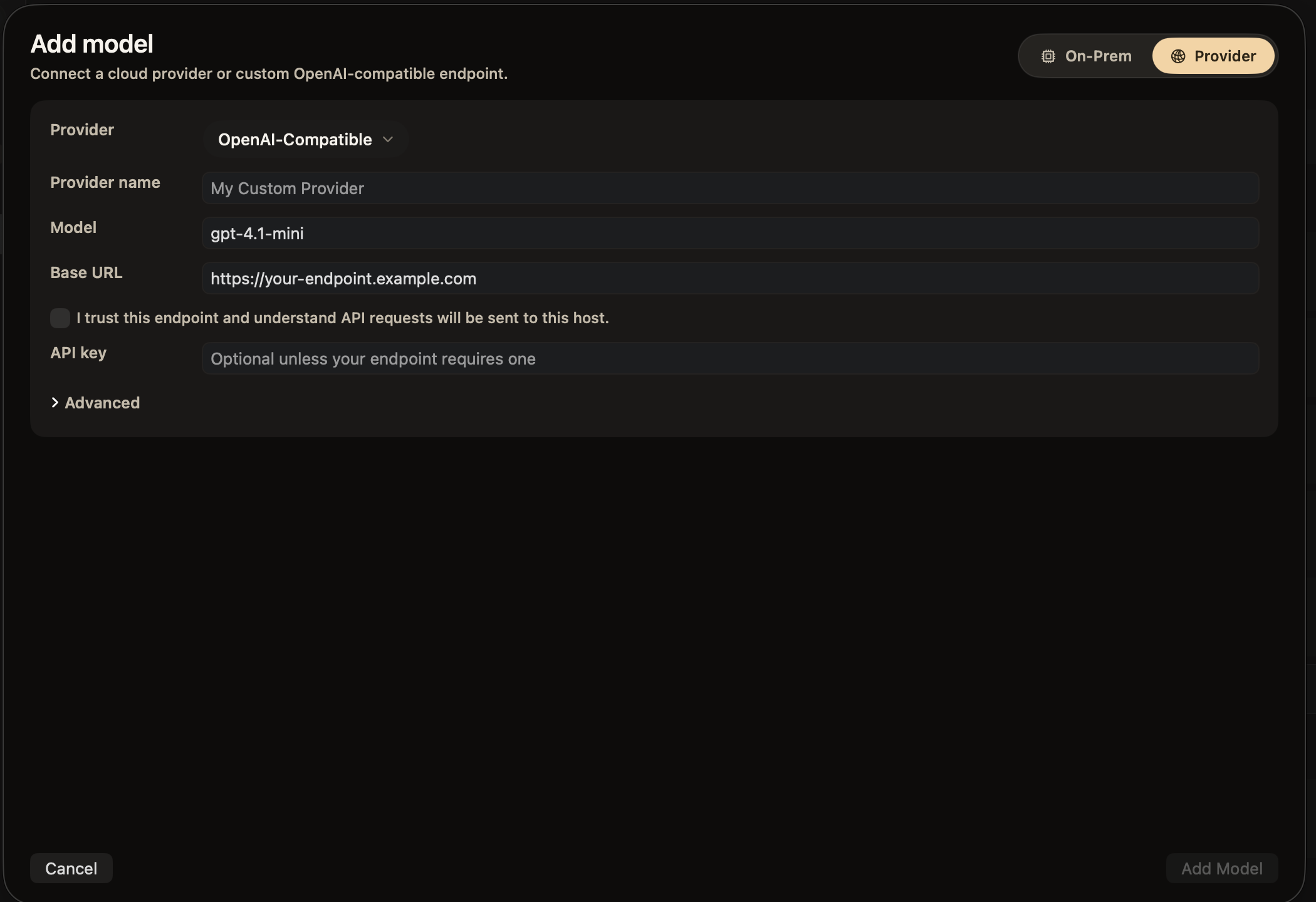
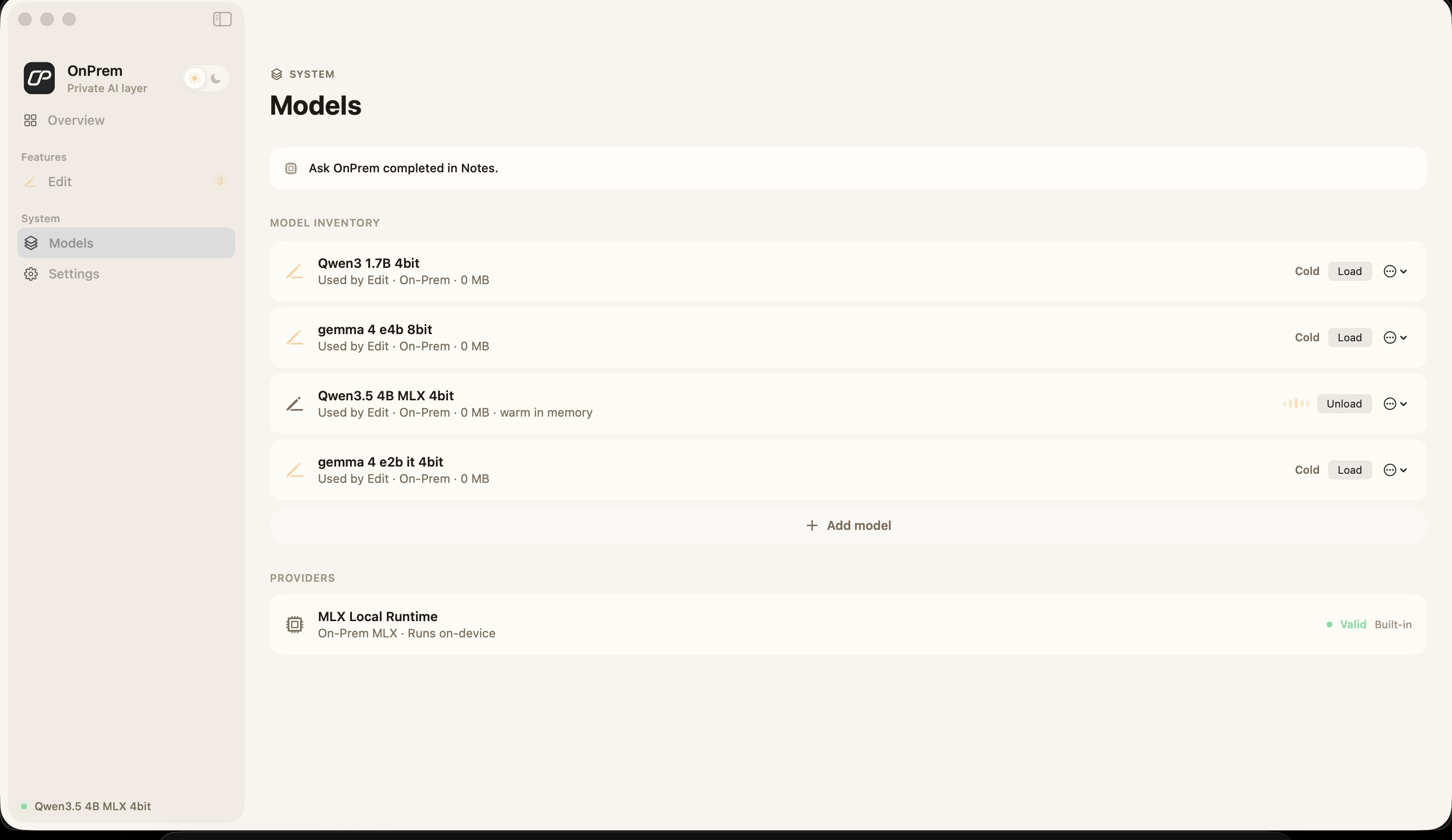
Run any open-source model directly on your laptop — or bring your own API key for the jobs that need a bigger brain. Either way, you stay in control.